From AI Pilot to Production: Scaling Enterprise AI Agents Beyond the Proof of Concept
The numbers tell a stark story. Industry surveys consistently show that while enterprise investment in AI agent technology is surging, only 14% of organisations have production-ready AI agent solutions in place — and just 11% are actually running agents in production at scale. Meanwhile, Gartner predicts that 40% of enterprise applications will embed task-specific AI agents by the end of 2026. The gap between where most organisations are and where the market is heading is significant, and it is widening.
For many organisations, this gap has a specific shape: a successful pilot. The proof of concept worked. Stakeholders were impressed. The AI agent demonstrated that it could handle the target workflow — processing invoices, resolving support tickets, drafting procurement recommendations, or triaging engineering alerts — with accuracy and speed that justified the investment. And then, somewhere between the pilot and the production deployment plan, progress stalled.
This article addresses that gap directly. It is not about whether AI agents can add value in enterprise contexts — that question was settled in 2024. The question now is why so few organisations are successfully scaling AI agents to production, what the specific barriers are, and what a structured path from proof of concept to full enterprise deployment actually looks like. This is the territory that matters for CTOs and AI programme leads in 2026: not whether to deploy, but how to do it without the pilot success evaporating under production conditions.
Why Pilots Succeed and Productions Fail
Understanding the pilot-to-production gap requires understanding why the two environments are fundamentally different, not just in scale but in the conditions they impose on an AI agent.
A pilot is optimised for demonstrating capability. The data is clean, the scope is narrow, the edge cases are excluded, and the success criteria are defined to showcase what the technology can do. A production environment is optimised for nothing — it is the full complexity of an enterprise operation, with the data quality issues, the edge cases, the concurrent users, the integrations that behave unexpectedly under load, and the organisational expectations that the system will simply work, every time.
Three categories of failure account for most stalled AI agent deployments:
Reliability failures. The pilot handled 200 test cases cleanly. Production handles 10,000 real cases per week, and 3% of them trigger failure modes that nobody anticipated. At pilot scale, a 3% failure rate is 6 edge cases that get escalated and manually handled. At production scale, it is 300 failures per week, each requiring human intervention, each eroding confidence in the system.
Cost failures. The pilot budget covered API costs for a bounded test set. Production volumes reveal that the agent architecture is economically unviable at scale — the LLM inference costs, combined with the retrieval, tool invocation, and orchestration overhead, make each transaction more expensive than the human process it was meant to replace.
Operational failures. Nobody built the monitoring. Nobody defined the alerting thresholds. Nobody established the rollback procedure when an agent behaves unexpectedly. Nobody owns the agent in production the way they own a traditional software system. The pilot was an experiment; production is a commitment the organisation is not structured to honour.
These are solvable problems. But they require treating the transition from pilot to production as an engineering discipline in its own right — not as a straightforward scaling exercise.
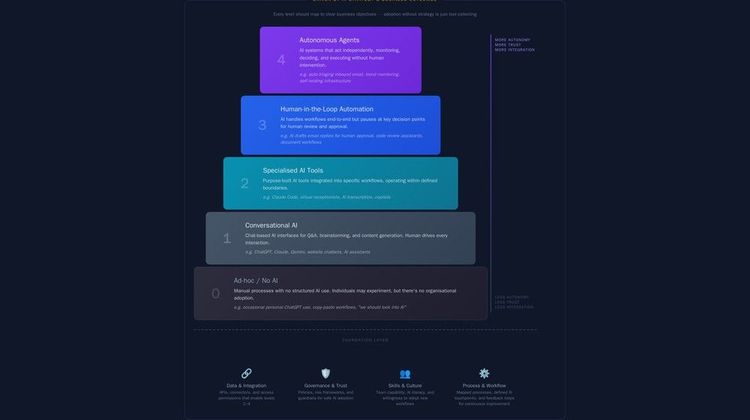
A Maturity Model for AI Agent Deployment
Before addressing the specific technical and operational requirements, it is useful to establish a framework for where your organisation sits and what the path forward looks like. The following maturity model describes the progression from initial proof of concept through limited production to full enterprise deployment, with the defining characteristics and key metrics at each stage.
Stage 1: Proof of Concept
At the PoC stage, an AI agent has been built and validated against a representative but controlled dataset. The primary goal is demonstrating that the agent can perform the target task with acceptable accuracy.
Defining characteristics:
- Narrow scope: single task or workflow, clean input data
- Manual evaluation of outputs against ground truth
- No integration with live production systems
- Success measured by task accuracy on test set
- No operational infrastructure (monitoring, alerting, logging)
Key metrics: Task accuracy on test set (target: >85% depending on use case), latency on representative inputs, estimated cost per transaction at target volume.
The exit criteria: The PoC proves that the agent is technically capable. It does not prove that it is operationally viable. Moving to limited production requires shifting from demonstration to engineering.
Stage 2: Limited Production
At the limited production stage, the agent handles real workloads in a constrained scope — a subset of transaction types, a single business unit, or a capped volume — with human review mechanisms and clear escalation paths in place.
Defining characteristics:
- Real data, real users, real consequences (with guardrails)
- Structured human-in-the-loop review for outputs above a confidence threshold
- Basic monitoring and alerting operational
- Defined escalation paths for agent failures
- Cost tracking per transaction at real volumes
- Formal feedback loops from reviewers to improvement backlog
Key metrics: Production accuracy rate (target: >92%), escalation rate (target: <10% of transactions requiring human review), mean time to detection for agent failures, cost per transaction at actual volumes, user adoption rate among target users.
The exit criteria: Limited production validates operational viability. The agent handles real complexity, the escalation rate is within acceptable bounds, the cost model works, and the organisation has demonstrated it can operate an AI agent as a production system rather than an experiment.
Stage 3: Full Enterprise Deployment
Full enterprise deployment means the agent operates at scale across the target scope, with production-grade reliability engineering, comprehensive governance, and the change management infrastructure to sustain adoption.
Defining characteristics:
- Full target volume and scope
- Automated quality monitoring with statistical process control
- Governance framework covering approval authorities, audit trails, and policy compliance
- SLA commitments with defined remediation procedures
- Integration with enterprise security and identity infrastructure
- Established feedback loop from production telemetry to model improvement
Key metrics: System availability (target: 99.5%+ for business-critical agents), accuracy drift detection (automated alerts when accuracy degrades >2% from baseline), cost per transaction against target unit economics, NPS or user satisfaction from agent-assisted workflows, time-to-escalation for agent failures.
Technical Barriers to Production: What Actually Breaks
Reliability Engineering for Production Agents
The reliability challenges of agentic AI deployments differ from those of conventional software because the failure modes are probabilistic and emergent rather than deterministic and predictable. A conventional API either works or it does not. An AI agent can produce an output that is plausible, syntactically correct, and subtly wrong in a way that downstream systems or users may not catch immediately.
Production reliability engineering for AI agents requires:
Confidence scoring and threshold management. Every agent output should carry a confidence score or uncertainty estimate. Outputs below a defined confidence threshold should be routed to human review rather than acted upon automatically. Calibrating these thresholds requires operational data — you cannot set them accurately in a pilot environment.
Input validation before agent processing. Many agent failures originate in malformed, incomplete, or anomalous inputs rather than agent reasoning failures. Robust input validation — checking data completeness, format conformance, and value range plausibility before the agent processes the input — prevents a large class of production failures.
Idempotent tool invocations and transaction safety. If an agent invokes an external tool (calling an API, updating a database, sending a notification) and the operation fails partway through, what happens? Agents that invoke external tools in production must be designed around idempotent operations with explicit transaction semantics — the same operation applied twice must produce the same result, and partial failures must leave systems in a defined, recoverable state.
Graceful degradation under load. Define what the agent does when its dependencies (LLM APIs, retrieval infrastructure, external tool endpoints) are slow or unavailable. A production agent that fails silently or blocks indefinitely under load creates operational problems that are harder to resolve than a system that degrades gracefully with clear error states.
Latency Optimisation at Enterprise Scale
Pilot environments rarely impose meaningful latency constraints. A test suite that waits 8 seconds for each agent response is acceptable for evaluation. A production workflow where 10,000 employees wait 8 seconds for each response is not.
The latency profile of an AI agent in production is determined by several components: LLM inference latency (highly variable by model and provider), retrieval latency (vector search, database queries), tool invocation latency (external API calls), and orchestration overhead (the logic connecting these components). Each must be profiled and optimised separately.
Practical optimisations that routinely reduce end-to-end latency by 40-60%:
- Caching at the retrieval layer: Many agent queries retrieve the same or similar context. A cache over retrieval results with appropriate TTLs eliminates repeated vector search for common queries.
- Parallel tool invocation: Where an agent needs to call multiple independent tools, invoke them in parallel rather than sequentially. Sequential tool calls accumulate latency multiplicatively.
- Model selection by task: Reserve frontier model capacity for the reasoning steps that require it. Use smaller, faster, cheaper models for classification, routing, and formatting tasks within the same agent workflow.
- Streaming responses: For user-facing agents, streaming partial responses from the LLM as they are generated dramatically improves perceived latency even when total time is unchanged.
Cost Management at Scale
The economics of an AI agent change substantially between pilot and production. A pilot budget covers hundreds or thousands of LLM inference calls. Production volumes involve millions. The cost model that seemed acceptable on a pilot budget often becomes untenable when extrapolated to full production volume.
The key levers for cost management in production AI agent deployments:
Token efficiency. Every token sent to and received from an LLM costs money. Bloated system prompts, verbose retrieval outputs, and over-specified instructions inflate costs without improving accuracy. Systematic prompt engineering — trimming context to the minimum that preserves accuracy — is worth more than most engineering teams assume.
Tiered model deployment. Not every agent task requires a frontier model. A triage agent that classifies incoming requests and routes them to the appropriate specialist agent can use a model that costs a fraction of the frontier model price. A document summarisation agent does not require the same reasoning capability as an agent making compliance decisions. Map your agent architecture to the model capability each task genuinely requires.
Volume-based commercial arrangements. At enterprise production volumes, usage-based API pricing becomes negotiable. Engage your LLM provider commercially once you have validated production volumes — the difference between list pricing and negotiated enterprise pricing at scale is material.
Caching for repeated patterns. Semantic caching — where similar queries are served from cached responses rather than generating a new LLM response — can reduce token consumption by 20-40% for agent workloads with significant query repetition.
Operational Requirements: Monitoring, Alerting, and Rollback
The operational infrastructure that production AI agents require is distinct from conventional software monitoring. Standard infrastructure metrics (CPU, memory, error rates) are necessary but not sufficient. You also need to monitor the quality of what the agent is doing.
Production monitoring for AI agents should include:
- Accuracy drift monitoring: Track the distribution of agent outputs over time. Statistical process control methods (control charts, CUSUM algorithms) can detect when the distribution of outputs drifts from the baseline established during validation — an early warning of degraded accuracy before it becomes visible as user complaints.
- Confidence score distribution: Monitor the distribution of agent confidence scores. A sustained shift toward lower confidence scores indicates the agent is encountering input patterns it is less certain about — often a precursor to accuracy degradation.
- Escalation rate tracking: Monitor the rate at which agent outputs are being escalated to human review or overridden by users. An increasing escalation rate is a leading indicator of accuracy problems.
- Latency percentile tracking: Monitor p50, p95, and p99 latency, not just average latency. Tail latency problems that affect 1% of requests are invisible in average metrics but highly visible to the users experiencing them.
Rollback strategy is an operational requirement that is frequently overlooked until it is urgently needed. Define before deployment what the rollback procedure is if the agent produces a sustained accuracy degradation or catastrophic failure. This means: what system state needs to be restored, who has authority to invoke a rollback, what the fallback process for handling the affected workload is, and how quickly the rollback can be executed. A rollback plan that exists only as a vague intention to “switch it off” is not a rollback plan.
Data Pipeline Engineering for Production Agent Workloads
The retrieval-augmented generation (RAG) architectures that underpin most enterprise AI agents in 2026 depend on data pipelines that are often underestimated as an engineering challenge. The pilot may have used a static document corpus processed once before the demo. Production requires continuous data pipelines that keep the agent’s retrieval context current, accurate, and clean.
Production data pipeline requirements for agent workloads:
Incremental ingestion: As source documents change, new documents are created, and outdated documents are retired, the vector index must be updated accordingly. Stale retrieval context produces confidently wrong agent outputs — a failure mode that is particularly damaging because the outputs appear authoritative.
Data quality controls at ingestion: The quality of agent outputs is bounded by the quality of retrieved context. Chunking strategy, metadata tagging, deduplication, and content quality filtering at the ingestion stage directly affect retrieval relevance and agent accuracy. These controls need to be part of the data pipeline, not a one-off exercise done before the pilot.
Retrieval evaluation: Monitor retrieval relevance in production using metrics such as recall at k (are the right documents appearing in the top-k results for representative queries?) and mean reciprocal rank. Retrieval relevance degrades as the corpus evolves, and this degradation must be detected and addressed before it degrades agent accuracy.
Security and Access Control for Autonomous Agents
When an AI agent is authorised to interact with enterprise systems autonomously — reading data, calling APIs, updating records, sending communications — the security model must be designed with the same rigour as any other system with enterprise access.
Principle of least privilege: Each agent should be authorised only for the specific operations it requires for its defined task. An agent that summarises customer support tickets does not need write access to the customer record system. Scope authorisation explicitly and review it regularly.
Agent identity and authentication: Agents must authenticate to enterprise systems using identities that are distinguishable from human user identities. This enables proper audit trails, allows agent access to be revoked independently of human user accounts, and prevents agents from inheriting the permissions of the human users who deploy them.
Prompt injection defences: Production AI agents that process external content (user inputs, emails, documents, web pages) are vulnerable to prompt injection attacks — where malicious instructions embedded in processed content attempt to redirect the agent’s behaviour. Input sanitisation, instruction hierarchy enforcement, and output validation are the primary defences and must be implemented as part of production security controls.
Audit logging for regulatory compliance: Every agent action — what data was retrieved, what tools were invoked, what decisions were made — must be logged with sufficient fidelity to support audit and compliance requirements. The audit trail for an autonomous AI agent is not the system logs of the LLM API; it is the structured record of agent reasoning and action that compliance teams can examine.
Change Management and User Adoption
Technical readiness is necessary but not sufficient for production success. The agentic AI enterprise deployment strategy that fails most often is not the one that gets the technology wrong — it is the one that gets the change management wrong.
The organisational dynamics of AI agent deployment are not straightforward. Users who see the agent as a threat to their roles will find subtle ways to undermine it — providing poor quality inputs, overriding agent outputs reflexively rather than selectively, or declining to use the system at all. Managers who do not understand what the agent is doing will not trust it with consequential decisions.
Effective change management for AI agent deployment includes:
- Transparent communication about what the agent does and does not do: Overpromising capability creates trust deficits when edge cases surface. Users who understand the agent’s scope and limitations are better positioned to use it effectively.
- Progressive autonomy expansion: Start with the agent in an advisory capacity, where its outputs inform human decisions rather than replacing them. Expand agent autonomy as user confidence and measured accuracy justify it. This is the limited production stage of the maturity model — and it serves a change management purpose as much as a technical one.
- User feedback mechanisms: Build feedback mechanisms that allow users to flag incorrect agent outputs and provide corrections. This serves both the operational monitoring purpose (tracking escalation rates) and the cultural purpose — users who can influence agent behaviour feel agency rather than displacement.
- Success story communication: As the agent delivers measurable value — time saved, error rates reduced, throughput increased — communicate those outcomes actively. Production adoption compounds when users see evidence that the system delivers on its promise.
Governance Frameworks That Enable Progressive Deployment
The enterprise AI governance framework 2026 landscape has matured considerably from the early, aspirational policy documents of 2023-2024. Organisations deploying agents in production need governance that is operationally functional, not just philosophically sound.
A governance framework for production AI agent deployment should address:
Approval authorities and decision boundaries: Define explicitly what decisions an agent is authorised to make autonomously, what decisions require human confirmation, and what decisions agents are categorically excluded from. These boundaries should be documented, enforced technically where possible, and reviewed periodically as the agent’s track record develops.
Model change governance: When the underlying LLM is updated by the provider, or when you change the retrieval corpus, the system prompt, or the tool definitions, what validation is required before the change is deployed to production? Model changes that would be inconsequential in a conventional software system can materially affect agent behaviour. A change control process for AI agent configuration is a production governance requirement.
Incident classification and response: Define what constitutes an AI agent incident (incorrect output with material consequence, unexpected behaviour, security event), what the escalation and response procedure is, and who has authority to invoke remediation actions. This should be part of the existing incident management framework, not a separate process.
Periodic accuracy review: Establish a cadence for reviewing agent accuracy against updated ground truth. The agent’s performance envelope may shift as the operational context changes — new product lines, revised policies, updated regulatory requirements. Periodic review catches drift that continuous monitoring may not detect.
The Path Forward for UK Enterprises
For UK organisations navigating the agentic AI enterprise deployment strategy in 2026, the pilot-to-production gap is a real but tractable challenge. The organisations closing it most successfully share a common characteristic: they treat the transition as a distinct engineering and organisational programme, not as a straightforward extension of the pilot.
The scaling AI agents production enterprise challenge requires five things to come together simultaneously: reliability engineering that handles production complexity, cost management that validates unit economics at scale, operational infrastructure that provides genuine observability into agent behaviour, security and governance frameworks that satisfy enterprise and regulatory requirements, and change management that builds rather than erodes user trust.
None of these are uniquely AI problems. They are engineering and organisational disciplines applied to a new category of system. The organisations that have successfully deployed agentic systems at scale are those that approached production deployment with the same rigour they apply to any complex enterprise system — not those that assumed that because the pilot worked, production would follow naturally.
How McKenna Consultants Supports Production AI Agent Deployment
McKenna Consultants works with UK enterprises that have demonstrated AI agent capability in pilot and need to close the gap to production deployment. Our AI consultancy for production deployment covers the full transition: reliability engineering and architecture review, cost modelling and optimisation, monitoring and observability design, security and access control implementation, governance framework development, and the change management support that determines whether production adoption succeeds or stalls.
We do not start from scratch — we work with the pilot infrastructure you have built and the organisational context you are operating in. Our approach is to identify the specific barriers between your current position and production readiness, address them in a structured programme, and leave you with the operational capability to run AI agents as production systems rather than perpetual experiments.
If your organisation has a successful AI pilot that has not yet made it to production, contact us to discuss a structured path to deployment.
Conclusion
The statistics are a useful anchor: 14% of organisations with production-ready AI agent solutions, 11% running agents in production, and a Gartner prediction that 40% of enterprise applications will embed task-specific AI agents by end of 2026. The implication is not that the technology is failing — it is that the discipline of production deployment has not kept pace with the enthusiasm for pilot experimentation.
The AI pilot to production enterprise UK challenge in 2026 is not primarily a technology problem. It is an engineering discipline problem: reliability engineering, cost engineering, operational engineering, security engineering, and the organisational engineering of change management and governance. Organisations that approach it as such — with the same structured rigour they apply to any production system — are the ones closing the gap and capturing the operational value that successful pilots have demonstrated is genuinely available.
The proof of concept proved the concept. Production proves the business case. The path between them is navigable, but it requires being walked deliberately.